
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 죠리퐁 라떼
- 메리 크리스마스 늑대아저씨
- VMware
- 선유도
- grid
- 실내운전연습실
- 일산실내운전연습장
- RAC
- oracle
- Linux
- Compression
- apache
- 달광
- 실내운전연습
- 낙서봉사단
- 감정날씨
- 일산실내운전연습실
- 11g
- 영문면허증
- 내 인생에 봄다방
- 그림책
- php
- homeschooling,
- 중문색달해수욕장
- MariaDB
- 도로주행
- 사랑해
- partition
- 아파치
- adr
- Today
- Total
소소한 일상에서 책읽기 중
Oracle 11g Data Compression 본문
source: dba-oracle.com
Column oriented data storage for Oracle
In traditional relational theory, the internal representation of the data on the physical blocks is not supposed to matter, but in the real world, the placement of the data on blocks is critical. Oracle provides tools like sorted hash clusters to group related rows together and row-sequencing can dramatically improve the performance of SQL queries by placing all information on a single data block.
Using Oracle cluster table, you can even group related tables together on the same data block. For example, if you have a busy OLTP database where millions of people query customer and related order rows all day long:

An un-clustered table has high I/O overhead
If you use Oracle cluster tables to put the customer and order rows together on a single data block, greatly reducing the number of trips to the database to fetch the desired result set.
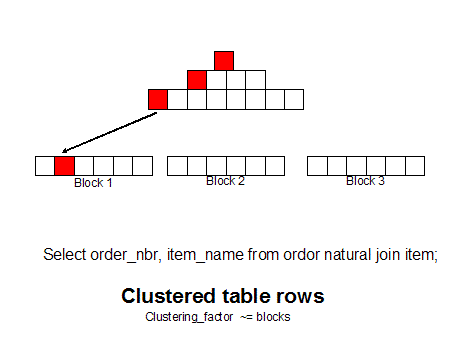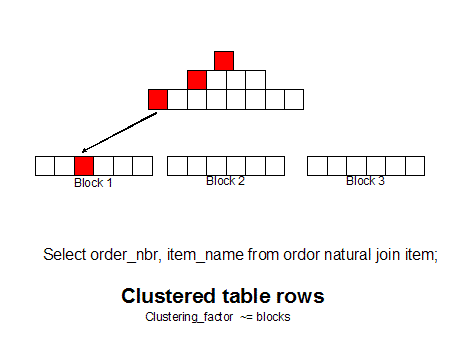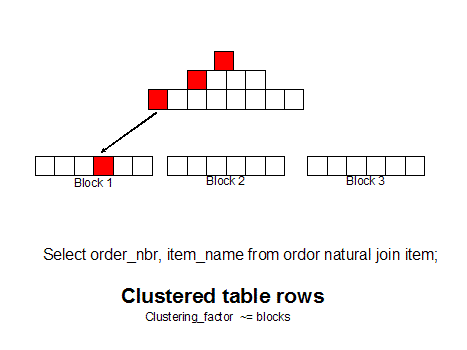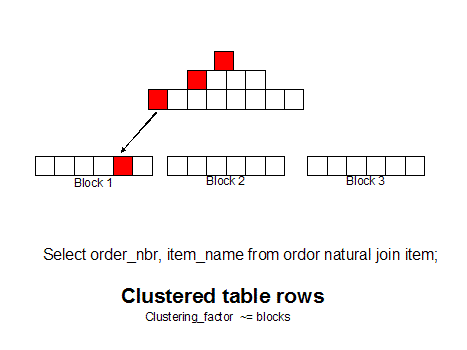
The placement of rows on physical data blocks makes a huge performance difference
See my note here on Oracle 11g table compression and note the tradeoff between run-time performance of the SQL, vs. the processing overhead of compressing and de-compressing the rows.
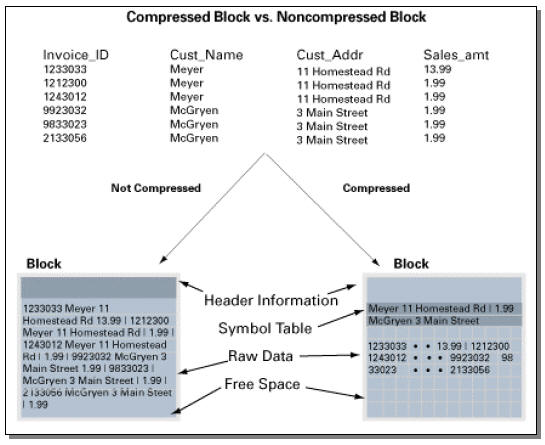
Source: Oracle Corporation
The point is that this type of compression requires overhead, and the less volatile the table, the better the overall performance.
11gR2 column level data storage for Exadata servers
These column oriented database have another significant advantage, because they store adjacent column data, they can use compression algorithms to detect patterns in the columns and achieve very high rates of data compression. This packs more data onto each data block, making data warehouse queries run even faster.
But what about applications like DSS that want data stored with related columns on the data blocks? While traditional database system wants to group related data items together, data warehouse applications prefer to see related columns of data grouped together on the data blocks.
In a OLAP or DSS system, we are analyzing "facts", individual column values, and we rarely needs row-oriented data display. Hence, it does not make sense to physically store data in rows format. Instead, we break-apart the rows and store the column values adjacent to one another on the data blocks.
Oracle guru Guy Harrison of Quest Software has this great illustration of rows storage vs. column storage on Oracle data blocks:

Source: Guy Harrison
This is very foreign to most relational databases, and column oriented database are similar to indexes, in that they store ROWID and column value pairs together on the data blocks. These column oriented databases were first implemented of guru’s like professor Michael Stonebreaker at MIT with their C-store column-oriented database.
While the 11g compression is row-level compression we now see a Oracle 11g Release 2 new feature called 11g column-level compression.
This option is only available on the Oracle/HP Exadata storage devices, million dollar firmware disks that are optimized for data warehouse data.
The column level compression for a table has syntax like this:
create table
tot_sales_compressed
compress for
archive level=3
as
select
sales_facts
from
sales s;
Note the archive level syntax. According to the Oracle documentation, the archive level arguments s[specifies the amount of compression, and this is directly related to the processing overhead at compress-decompress time.
Oracle guru Guy Harrison of Quest Software performed a benchmark on the 11g Release 2 compression with these results:

Today, it appears that this new column-level data storage is only available on the million dollar Exadata storage boxes being sold by Oracle and HP. If you attempt to define column-level compression on a non Exadata server to get this error message:
ORA-64307: hybrid columnar compression is only supported in tablespaces residing on Exadata storage
Cause: An attempt was made to use hybrid columnar compression on unsupported storage.
Action: Create this table in a tablespace residing on Exadata storage or use a different compression type.
Oracle11g compression syntax
The 11g docs note that the new COMPRESS keyword works for tables, table partitions and entire tablespaces. Oracle has implemented their data compression at the table level, using new keywords within the "create table" DDL:
create table fred (col1 number) NOCOMPRESS;
create table fred (col1 number) COMPRESS FOR DIRECT_LOAD OPERATIONS;
create table fred (col1 number) COMPRESS FOR ALL OPERATIONS;
alter table fred move COMPRESS;
We also see syntax for creating a compressed tablespace:
CREATE TABLESPACE MYSTUFF . . . DEFAULT{ COMPRESS [ FOR { ALL | DIRECT_LOAD } OPERATIONS ]
| NOCOMPRESS
}
Several DBA views have been enhanced in 11g to show compression attributes. The dba_tables view has added the new columns COMPRESSED (enabled, disabled) and COMPRESSED_FOR (nocompress, compress for direct_load operations, compress for all operations).
While powerful, Oracle11g has made some important fundamental decisions about mixed-mode compression, a feature whereby it is possible for rows within the same table to be either compressed or uncompressed! The expected behaviors for the new compression syntax has a few surprises, features that require knowledge of how Oracle has chosen to implement their data compression utility.
Oracle's multi-state compression
While the "alter table" and "alter tablespace" clauses support changing the compression options, we would expect that Oracle would feel obligated to change all objects to match their new compression attributes. That is not the case, and the 11g compression docs note that a table may have multi-state rows, some compressed and others expanded:
You can alter the compression attribute for a table (or a partition or tablespace), and the change only applies to new data going into that table.
As a result, a single table or partition may contain some compressed blocks and some regular blocks. This guarantees that data size will not increase as a result of compression; in cases where compression could increase the size of a block, it is not applied to that block.
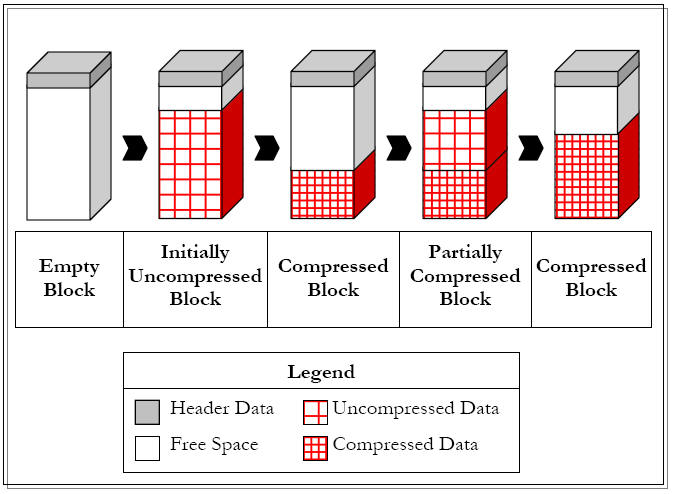
Oracle 11g multi-state blocks (Source: Oracle Corporation)
Without implementing this revolutionary "partial" row compression, making a table-wide or tablespace-wide compression change would require a massive update to blocks within the target tablespace. The 11g compression docs note that when changing to/from global compression features, the risk averse DBA would choose to rebuild the table or tablespace from scratch:
Existing data in the database can also be compressed by moving it into compressed form through
ALTERTABLEandMOVEstatements. This operation takes an exclusive lock on the table, and therefore prevents any updates and loads until it completes.If this is not acceptable, the Oracle Database online redefinition utility (the
DBMS_REDEFINITIONPL/SQL package) can be used.
'DB까다롭다' 카테고리의 다른 글
| 11gR2 new features (1) | 2011.04.19 |
|---|---|
| Oracle 11g Architecture with diagram & new features (3) | 2011.04.19 |
| 11g Data Compression - too much overhead? (0) | 2011.04.19 |
| Oracle 11g Data Compression Tips for the Database Administrator (2) | 2011.04.19 |
| 10g Workshop 7장 (0) | 2011.01.04 |